| Gojomo | |
|
2006-11-30
NASA's d366 bug
Perhaps you've heard of the 'y2k bug', where software wasn't ready for dates rolling from 1999 to 2000. Turns out NASA's space shuttle software has a d366 bug every new year's eve: NASA wants Discovery back from its 12-day mission by New Year's Eve because shuttle computers are not designed to make the change from the 365th day of the old year to the first day of the new year while in flight.I'm surprised NASA's space systems care about calendar years at all. I would have expected them to use some other reference frame, like say seconds since the moon landing. Tags: nasa, space+shuttle, , software, bug, y2k, d366 «» (2) comments
2006-11-13
I, for one, welcome our new... *rat-tat-tat-tat-tat*
NewLaunches.com (via Slashdot) Samsung develops machine gun sentry robot costs $200k: Samsung has partnered with Korea university and developed the machine-gun equipped robotic sentry. It is equipped with two cameras with zooming capabilities one for day time and one for infrared night vision. It has a sophisticated pattern recognition which can detect the difference between humans and trees, and a 5.5mm machine-gun. The robot also has a speaker to warn the intruder to surrender or get a perfect headshot. The robots will go on sale by 2007 for $ 200,000 and will be deployed on the border between North and South Korea.I've fought similar things in Half-Life. I wonder when Samsung will come out with those flying chainsaws from Half-Life 2? Tags: scary, robots, samsung, military, machine+guns, half+life, dmz, save+us,+john+connor «» (0) comments
2006-11-06
Famous people like me!
I feel so lucky. Both Arnold Schwarzenegger and Clint Eastwood have called in the last 30 minutes. That's a big step up from the other day, when it was only former California state treasurer Matt Fong. I wonder who'll call me next week? Tags: california, politics, telemarketing, campaigning, facetious, robocalls «» (0) comments
2006-10-11
Nominative Determinism: YouTube vs. 'Google _[blank]_'
Just when I thought Google had come to appreciate the value of a killer name -- buying a great brand in YouTube -- they roll out the most generic and uninspired product name since, well, 'Google Video': Google Docs & Spreadsheets. Say that three times fast. A name like this even creates cognitive dissonance with the widely-understood verb form 'to google'. I know capital-G Google has to fight such word usage to defend their trademark -- but such usage still benefits them, by worming their identity ever deeper into the common understanding of search. To the extent boring names like 'Google Video' or 'Google Docs and Spreadsheets' work at all, they also read as imperative statements using that verb: "google (that is, search) video" or "google (that is, search) docs and spreadsheets". The value proposition of these offerings go beyond search... but their potential identities are being smothered under the 'Google' uber-brand. Give them some breathing room: stop the parade of "Google ______" offerings and cook up alternates with their own personality and attitude, like YouTube. Tags: google, youtube, gootube, branding, naming, google+docs+and+spreadsheets «» (2) comments
2006-09-12
Another mechanism for Peltzman Effect?
The Peltzman Effect is the hypothesized tendency of people to react to a safety regulation by increasing other risky behavior, offsetting some or all of the benefit of the regulation. I had always thought of this as driven by the behavior of the people 'protected' -- they take extra risks. Turns out in the case of bicyclists, drivers nearby may take more risks when seeing a cyclist in a helmet. University of Bath: Wearing a helmet puts cyclists at risk, suggests research Drivers pass closer when overtaking cyclists wearing helmets than when overtaking bare-headed cyclists, increasing the risk of a collision, the research has found.Update: I just noticed that the researcher's title is traffic psychologist. I wonder: does he find psychoanalysis or pharmacotherapy better at controlling traffic? Can we get 'failure to signal' into DSM-IV? When I dream I'm in a flying car, what does that mean? Tags: peltzman+effect, safety, helmets, regulation, cycling «» (0) comments
2006-09-08
Donating labor to forge your own shackles
In a comment at an O'Reilly Radar post about Google Image Labeler, Thomas Lord throws a little cold water on crowdsourcing euphoria: We ought to worry about the conjunction of (a) a return to the days of exchanging labor for goods and services by barter; (b) a very, very, very, (very) low price for labor; (c) the direction of of said cheap labor to the creation and improvement of privately held databases of non-trivial utility in population manipulation; (d) the difficulty of even experts to grasp the signficance of these databases, nevermind the average laborer who contributes to them. George Dyson just keeps sounding more and more right.Not so worried about (a) specificially -- voluntary trade of any for any is AOK AFAIC -- but (b), (c), and (d) might have sharp edges in the future. Handle with care! Tags: crowdsourcing, pessimism, contrarianism, thomas+lord, open+data, privacy «» (0) comments
I need a montage: vicarious Burning Man
If you missed Burning Man (like I did), Sean McCullough has some great Burning Man 2006 Photos and a video montage set to music. Tags: burning+man, cricketschirping «» (0) comments
2006-09-01
Web 2.0 marketing, $900/minute
Carson Workshops: Five Minutes of Fame (PDF)
FIVE MINUTES OF FAME There is a fee of $4500 USD for each five minute slot.Tags: marketing, web2.0, carson+workshops, «» (0) comments
2006-08-20
Brain fertilizer?
They call it bullshitr: Web 2.0 Bullshit Generator. But maybe it's just a domain-specific Oblique Strategies deck?
2006-08-08
Dropping the O-Bomb
Zack Lynch: Trust, Happiness and Societal Development The major finding [of neuoreconomist Paul Zak and Ahlam Fakhar] is that factors that raise overall levels of oxytocin and/or estrogens (which increase oxytocin uptake) affect country-level measures of trust. Most prominently, these include the consumption of healthy foods (especially vegetables and fruits), clean environments, and some social behaviors. These are independent of the economic and legal factors that support trust and therefore provide a new rationale for governments and NGOs seeking provide healthier environments in developing countries: raising trust stimulates economic growth. Lastly, the strongest factor by far associated with a country's level of trust is...self-reported happiness. While the causation is likely bidirectional, we now know that trusting people are happier.I suppose dropping oxytocin bombs across the middle east would run afoul of chemical weapons treaties. Previously: Paging Dr. Strangelove: Air Force considered 'sex bomb' Tags: oxytocin, neuroeconomics, brainwaves, middle+east, economics, trust «» (0) comments
2006-08-07
The 'Long Tail' of tail: crowdsourcing pioneer Joe Francis
Volunteer-generated content. The amateurization of media. Crowdsourcing. "Girls Gone Wild" has been on the leading edge of Media 2.0 trends since the late 90s. Claire Hoffman profiles its founder, Joe Francis: LA Times: 'Baby, Give Me a Kiss' The "Girls Gone Wild" empire is built on a "Long Tail" of tail: a seemingly-inexhaustible population of drunken young women, seizing the momentary exhilaration of exhibitionism plus a minute or two of direct-to-video porn-fame. Camera crews with giveaway t-shirts, panties, and hats create an "architecture of participation" which generates the "emergent, not predetermined user behavior" of spontaneous public nudity -- and then more raunchy behavior back in hotel rooms and the "Girls Gone Wild" party tour buses. And if Francis invites you back to the bus bedroom, he may even show you his version of "small pieces, loosely joined" -- whether you want him to or not. Tags: long+tail, joe+francis, girls+gone+wild, crowdsourcing, porn, facetious «» (1) comments
2006-08-04
Everything you know is wrong, economics edition
Monopoly and oligopoly firms don't earn higher returns, according to research by Kewei Hou of Ohio State and David T. Robinson of Fuqua (Duke). Their paper, Industry Concentration and Average Stock Returns, finds: Firms in more concentrated industries earn lower returns, even after controlling for size, book-to-market, momentum, and other return determinants. Explanations based on chance, measurement error, capital structure, and persistent in-sample cash flow shocks do not explain this finding. Drawing on work in industrial organization, we posit that either barriers to entry in highly concentrated industries insulate firms from undiversifiable distress risk, or firms in highly concentrated industries are less risky because they engage in less innovation, and thereby command lower expected returns. Additional time-series tests support these risk-based interpretations.(HT: Paul Kedrosky) Meanwhile, 25 years of giant trade deficits haven't changed the United States to a debtor nation, according to Harvard's Ricardo Hausmann and Federico Sturzenegger. In their paper U.S. and global imbalances: can dark matter prevent a big bang?, they suggest the United States has remained in the same net creditor position for decades: In a nut shell our story is very simple. The income generated by a country’s financial position is a good measure of the true value of its assets. Once assets are valued accordingly, the US appears to be a net creditor, not a net debtor and its net foreign asset position appears to have been fairly stable over the last 20 years. The bulk of the difference with the official story comes from the unaccounted export of knowhow carried out by US corporations through their investments abroad, explaining why the US appears to be a consistently smarter investor, making more money on its assets than it pays on its liabilities and why the rest of the world cannot wise up. In addition, the value of this dark matter seems to be rather stable, indicating that they are likely to continue to compensate for the measured trade deficit.(HT: Bryan Caplan) Finally, the officially reported 2005 federal budget deficit came in around $300 billion, lower than the originally expected $400 billion. But, if tallied using the same rules that apply for private companies, the 2005 federal budget deficit was $760 billion. And, once increases in Social Security and Medicare liabilities are counted, the 2005 deficit was actually $3.5 trillion. Yes, that's deficit not debt and trillion with a 't'. Dennis Cauchon covered the issues in his USA Today story, What's the real federal deficit? -- and the problem reaches back even to the 'surplus' years of the late 90s: Congress and the president are able to report a lower deficit mostly because they don't count the growing burden of future pensions and medical care for federal retirees and military personnel. These obligations are so large and are growing so fast that budget surpluses of the late 1990s actually were deficits when the costs are included.Tags: economics, trade+deficit, budget+deficit, deficits, debt, accounting, monopoly, oligopoly «» (0) comments
2006-07-24
Leniency to the enemy? Mao more than ever!
James Hailer in the Washington Post: Detainees, if Freed, Could Help U.S.
The late David Galula, whose book "Counterinsurgency Warfare: Theory and Practice" is considered by many to be the bible of counterinsurgency, wrote about his experience more than 50 years ago:Tags: guantanamo, mao, counterinsurgency, terrorism, gwot «» (0) comments
2006-07-11
Bitpedia gets a blog
Bitpedia, the collaborative online reference work stewarded and published by Bitzi, finally has a blog: Bitpedia Blog: about the digital media encyclopedia Tags: bitzi, bitpedia, bitcollider «» (0) comments
2006-07-06
Obamamandering
The Economist suggests there would be fewer polarizing politicians, and especially marginalized, highly partisan black politicians, if not for gerrymandering: The Economist: Faith, race and Barack Obama They're right... and many other corruptions of modern American politics could be lessened if incumbents weren't so protected. We could easily, with today's mapping technology, make contiguous but completely partisan-indifferent districts. As an extreme example, California's 53 districts could each be horizontal stripes, having only latitudinal straight lines as drawn borders, with equal populations. (They'd be wider near Eureka, thin near big cities.) Odd, and tough on campaigners -- but still an improvement over today's noncompetitive districts. Other algorithms could satisfy 'compactness' as an ease to campaigning, as appropriate -- so long as partisan data is never fed into the algorithm as an input. (So far, the only deployment of advanced demographic technology in practice has been by the parties to assist their gerrymandering.) The Wikipedia article on gerrymandering discusses some possible algorithms. Perhaps a topic for Jimmy Wales' new Campaigns Wikia? Tags: politics, reform, campaigns, gerrymandering, elections, corruption, incumbents, wikia «» (0) comments
2006-06-29
"Cost Per Whatever" to displace CPC and CPA
Google Checkout and experiments in "cost-per-action" (CPA) advertising bring Google several steps closer to a "pay-per-click-you-like" future. What's that, you ask? Well, take CPC (cost-per-click) and CPA advertising as points on a continuous curve: CPC pays for every (or every 'legitimate') click, CPA only pays for clicks that result in sales. But in fact there are as many kinds of clicks as there are clickers, and every one has a different value. Further, this value is only evident at some time after the click is delivered. Was it a shallow click -- a confused customer or fraudster? Was it a valid lead that left contact info but may not purchase for weeks? Was it a small sale? A large sale? A sale that ultimately resulted in a return? With that insight, we can take a radical leap to a new model for pricing clicks: pay whatever you feel like, and only after you've decided what the click was worth to you. Pay nothing for clicks you don't like, after you've had time to evaluate them. (No more anguished appeals to PPC advertisers for fraud investigations!) "Huh? Wha? It'll never work!" you might protest. People will lie about what clicks are worth; they'll game the system; it's too complicated. But think it through, and you'll see there's a better alignment of incentives, and less opportunity for fraud and gaming, than with the current discontinuous and fixed-price CPC and CPA systems. Could an advertiser game Google, by underpaying for valuable clicks? Only at threat of having those exact same kinds of clicks dry up in future periods. If you want more of any particular click, you have to pony up. Conversely, by refusing to pay for worthless clicks of any kind -- by whatever criteria makes sense for your business, not magic secret 'fraud-detecting' algorithms deep in Google's bowels -- you'll send Google the best feedback possible about what clicks (and ad inventory/impressions) you want. Google won't be guessing what clicks are bad with algorithms; they'll be knowing because customers will have told them directly. Can a fraudster bilk advertisers? Only if they manage to simulate valuable clicktrails through target sites -- a much harder problem against diverse real businesses than generating simple clicks. And any business fearing fraud has the ultimate countermeasure completely in their own hands: just clam up and only pay for real, verified, unreturned sales. Is it too complicated? Small and unsophisticated advertisers can still pursue degenerate strategies: pay for every click, or pay for only sales. They can gradually vary their payments as their sophistication grows, or use free or subsidized tools like Google Analytics and Google Checkout to improve their pay-strategy. And yet, they'll still benefit from the info spillover of the sophisticated buyers. Google will learn from the 'pro' customers, who use powerful click-valuation software, which clicks are truly valuable. Further, it is in Google's self-interest to even send 'dumb' CPC buyers just enough true value to make their ad spend worthwhile (or else lose the customer). And Google? Such a system takes them even further towards being a giant and dominant click-routing brain, sending impressions to wherever they have the greatest expected click-value return, based on past payment patterns. As I noted last year in a post introducing an earlier variant of this idea: Google is uniquely positioned to implement and benefit from such a policy. They already rank AdWords ads not by raw bid, but by actual profitability over time. They already reserve for themself overwhelming placement discretion, and keep raw performance, price, and payout rates to themselves. All they ask of advertisers is, "are you getting sufficient value for value paid?" -- and that'd be the core proposition at the heart of a pay-per-click-you-like system, too. (Pay no attention to the half-million computers behind the curtain.)Call it cost-per-whatever (CPW). Let every click find its own value! But watch out for the proprietary click-intelligence monopoly it could create. (Previous entries on this topic: Killing click-fraud (and the competition) with one stone [March 14, 2005]; Google Analytics & the "pay-per-click-you-like" future [November 14, 2005] .) Tags: cost+per+click, cpc, cost+per+action, cpa, advertising, adwords, adsense, google, checkout, cost+per+whatever, click+fraud «» (1) comments
2006-06-25
You the man now, Digg!
I recall early this year when Digg was knocking at Slashdot's door, about to surpass it in traffic... but only in the last few days have I noticed a couple mention that Digg has actually pulled into the lead. According to Alexa, Digg passed Slashdot in tracked pageviews in March, then in tracked "reach" (which I believe is a matter of unique visitors) in April:
(Part of the Digg surge is associated with a discontinuity in the Alexa data which probably reflects some internal methodological change -- but the pro-Digg trend seems evident both before and after.) I always thought Slashdot could be unseated by a similarly-focused competitor that showed marginally more care about quality: facts, grammar, and a respectable editorial voice. How wrong was I? You the man now, Digg! Tags: slashdot, digg, traffic, alexa «» (0) comments
2006-06-24
But 5,271,009 women?
SFGate: Tech leaders, wannabes gather in San Francisco / Supernova2006 good for networking with Internet crowd 'There's a frenzy of startups,' said Markus Frind, founder of PlentyofFish.com, a free one-man online dating service in Vancouver, British Columbia."A "one-man online dating service"? What an interesting twist on online dating! That one man must be busy. I'm sure this also makes the site 'search' functionality a lot easier to code. Tags: facetious «» (0) comments
2006-06-22
Serial entrepreneurship
In 1896 Charles Pathé, with his brother Émile, founded Société Pathé Frères, an early motion picture equipment and content company. The company produced successful silent movie serials, including The Perils of Pauline. The Pathé brothers were thus serial entrepreneurs. Earlier, the brothers had founded a record company, Pathé Records, so the Pathé brothers were also serial entrepreneurs: starting multiple businesses. However, since only the second business concerned movie serials, they were not serial serial entrepreneurs. John Harvey Kellog, with his brother, Will Keith Kellogg, formed the Sanitas Food Company in the 1890s to sell whole grain breakfast cereals. They were cereal entrepreneurs. After a falling out, Will Keith broke off on his own, forming the Battle Creek Toasted Corn Flake Company -- which became the Kellogg we still know today. Will Keith Kellogg was a serial cereal entreprenuer! If only Dennis Hayes, founder of serial-modem seller Hayes Communications, would start a breakfast foods company. Then, he would be a serial serial-cereal entrepreneur. Tags: entrepreneurship, language, serial, cereal «» (1) comments
2006-06-12
Scoring yourself daily: Joe's Goals
via Reddit: Joe's Goals I've had the idea for a web app like this in the back of my mind for a while, so it's great to see it made real. But, some quibbles:
Tags: goals, gtd, joesGoals, website, review «» (1) comments
2006-06-06
Red Rain Andromeda Strain
Popular Science: Is It Raining Aliens? As bizarre as it may seem, the sample jars brimming with cloudy, reddish rainwater in Godfrey Louis’s laboratory in southern India may hold, well, aliens. In April, Louis, a solid-state physicist at Mahatma Gandhi University, published a paper in the prestigious peer-reviewed journal Astrophysics and Space Science in which he hypothesizes that the samples—water taken from the mysterious blood-colored showers that fell sporadically across Louis’s home state of Kerala in the summer of 2001—contain microbes from outer space.As a fan of the panspermia theory, I'd been meaning to post about this for a while. Now the Popular Science article has also been picked up by CNN, this red rain incident and accompanying extraterrestrial-life theory is getting wider attention. My «panspermia» tag at del.icio.us collects some of the coverage and research papers (including rejected versions) about the 'red rain' and other possible evidence for life elsewhere. Tags: panspermia, red+rain, extremophiles, exobiology, ETs «» (0) comments
2006-06-03
Joe Dunce for California Controller?
We're deep into primary election season in California, meaning broadcast TV is saturated with political advertising. A lot of it is unintentionally humorous -- the attacks between the Dem governor candidates, Steve Westley and Phil Angelides, have been especially funny, featuring flimsy appeals to the sort of cartoon-villain archetypes that might appeal to Dem primary voters: "evil real estate developer", "negative campaigner", "negative campaigner" (the other guy, now), "favor seller", "tahoe polluter", "friend of Schwartzenegger". My favorite unintentionally funny ad, though, is in the down-ticket race for the Dem controller nomination. The candidate, Joe Dunn, claims to be "the man who cracked Enron" because he chaired a committee investigating California's 2000-2001 energy crisis, including Enron's involvement. (Never mind that none of the recent convictions for Enron heads Kenneth Lay and Jeffrey Skilling had anything to do with Enron's operations in California.) However, Dunn's heavily-played TV commercial poses the question: can a man 'crack' Enron if he can't find it on a map? The 'action scenes' (set to 'action music') of the commercial are interspersed with tracings on a map showing Dunn's travels during his investigation. But here's the key frame, for me: 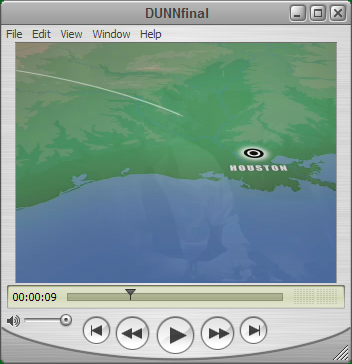
Astute students of geography will note that Dunn's team has rendered Houston on the Mississippi, deep in Louisiana, essentially where New Orleans is. (Or perhaps, to be precise, Baton Rouge.) The real Houston is about 300 miles west, where that other bay is on the left side of the Dunn ad frame. For those needing a refresher, here's a helpful map from the Washington Post: 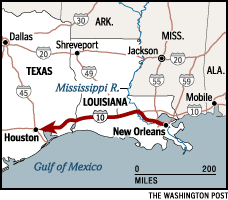
Now, neither gulf coast transplants nor the geographically astute are likely to be swing voters in the Dem primary. And perhaps it doesn't matter. For example, I can't find any other references to anyone who's noticed this error. But for the office of controller, the "Chief Financial Officer of California" who must "account for and control disbursement of all state funds" and "determine [the] legality and accuracy of every claim against the State" -- I'd rather have a 'detail guy'. Someone who sweats the small stuff, checks anything in doubt, and expects the same of his team. So bragging about an investigational trip to Houston, but plotting it on a map as New Orleans, just looks comically inept. (Dunn's opponent, John Chiang, has some cheesy TV ads good for grins too, especially as they show Chiang marching stiffly around downtown business districts, snapping law books shut, and finally staring sternly into the "wind" -- generated by a just-offscreen fan, no doubt. But they don't have the same whiff of incompetence about them as the Dunn ad, and it appears Chiang at least has some tax and finance experience compared to that of a grandstanding lawyer.) Tags: joe dunn, california, elections, controller, tv, politics, houston, new orleans, john chiang «» (0) comments
"Team Human" and still more on saluviruses
Reuters at ABC: We are not entirely human, germ gene experts argue "We are somehow like an amalgam, a mix of bacteria and human cells. There are some estimates that say 90 percent of the cells on our body are actually bacteria," Steven Gill, a molecular biologist formerly at TIGR and now at the State University of New York in Buffalo, said in a telephone interview.We might better think of ourselves as "team human": a flotilla of life teeming with many other species. A few years ago I suggested the term saluvirus for beneficial viruses, expecially those naturally-occurring. Slate has an interesting article on what were probably the first-discovered saluviruses: bacteriophages, viruses which kill bacteria. Daria Vaisman at Slate: The Soviet method for attacking infection The word phage comes from the Greek "to eat." A phage contains genetic material that gets injected into a virus's host. Whereas "bad" viruses infect healthy cells, phages target specific bacteria that then explode. At Eliava [phage research institue in former Soviet Georgia], phages are produced as a liquid that can be drunk or injected intravenously, as pills, or as phage-containing patches for wounds. Though few published articles in Western journals report positive clinical trials—most of the recent long-term research on phages comes out of the Soviet Union—some Western scientists say that phages are safe and that they work. "There is no evidence that phage is harmful in any way," says Nick Mann, a biology professor at the University of Warwick in England and co-director of phage R&D company Novolytics.I remember immediately thinking when I first learned about bacteriophages in high school biology that they could be a useful against harmful bacteria. I don't recall our curriculum addressing that possibility. An exicting part of the article is the prospect of custom phages for any bacterial strain, and constantly updated phage mixes much like constantly-updated flu vaccines. But US medical regulation would throw a monkey-wrench into such dynamic/active medicine: There are two ways that phages are currently used in the former Soviet Union, and both pose problems from the point of view of the Food and Drug Administration. At the Tbilisi phage center, phages are personalized: You send your bacterial sample to the lab, and it's either matched up with an existing phage or a phage is cultured just for you. In the United States, by contrast, drugs are mass produced, which makes it easier for the FDA to regulate them. Phages are also sold over-the-counter in Georgia. People take the popular mixture piobacteriophage, for example, to fight off common infections including staph and strep. These phage mixtures are updated regularly so they can attack newly emerging bacterial strains. In the United States, the FDA would want the phages in each new concoction to be gene sequenced, because regulations require every component of a drug to be identified. To do so would entail prohibitively expensive and lengthy clinical trials.There is some hope for Americans unable to travel to Georgia: "Phages might be offered someday at clinics on Native American reservations, as a casinolike quirk of legislative autonomy." One step beyond culturing phages from natural stocks would be designing synthetic disease-specific viruses -- and it turns out that's not just appropriate for bacterial disease, but cancer: New Scientist: Engineered virus thwarts ovarian cancer in mice Bartlett’s team created a modified vaccinia virus that would target and kill cancer cells. They did this by removing genes in the virus that help it to produce a growth protein. This means that the virus survives best in cancer cells that can supply it with large quantities of this growth protein, as opposed to non-cancerous cells that only produce very small amounts. The vaccinia virus was also engineered to carry a gene for an enzyme called cytosine deaminase that causes cell suicide in the cells it infects. Of the mice given the immediate injection, 90% were still alive 180 days later and showed no signs of tumour growth, says Bartlett.There are previous reports of naturally-occurring anti-cancer viruses. Perhaps spontaneous remissions from cancer are actually triggered by catching such a natural virus, purely by luck. Anyone enjoying such a fortuitous remission should thus be a prime hunting grounds for new saluviruses. The healthy should be under the microscope in the search for contagions nearly as often as the sick. Tags: saluvirus, phages, cancer, fda, medicine, bacteria, disease «» (0) comments
The war against metadata?
Piratbyrån's talk at Reboot 8.0: The Grey Commons
The war against file-sharing is essentially a war against the distribution of uncopyrighted metadata, not against the distribution of copyrighted material. It is about hindering the ever-present piracy from globalizing and open indexing, pushing it back to the family and the schoolyard and the workplace. Scaling-down, not in quantity but in network scale, from peer-to-peer to person-to-person. The result is not less piracy, but less plurality in piracy.Technorati Tags: piracy, piratbyran, pirate bay, metadata, file sharing, copyright, reboot, reboot8 «» (0) comments
2006-05-27
Blogger: Tear down this (robots) wall!
Blogger photo hosting: http://photos1.blogger.com/robots.txt
These rules prevent all respectful robots from fetching Blogger-hosted images on posts. Unfortunately, that means that (among other things), the Internet Archive's saved historical records of blog posts may often lack the images to go with the text.User-agent: * Disallow: / How about it, Blogger -- aren't the images important enough to allow robots to get them, too, whenever the author has allowed robots on the main text? Technorati Tags: blogger, robots.txt, internet archive, robots «» (0) comments
2006-05-10
GigaOM : Long Tail Is The New Hockey Stick
GigaOM : Long Tail Is The New Hockey Stick Awesome! I can just take my Web 1.0 hocket-sticks and rotate them 90-degrees clockwise to use in my Web 2.0 pitches! Technorati Tags: web2.0, long+tail, hockey+stick, facetiousness «» (0) comments
2006-05-03
Open source software development opportunities at the Internet Archive
The Internet Archive, where I work, is the home for a number of open source projects: We have current opportunities for both student and career open source software developers. We are looking for a full-time Java Software Engineer to complement our core team in San Francisco. We are also participating in the Google 2006 "Summer of Code" program which awards students a stipend for mentored work on open source projects. (Monday May 8th is the deadline to apply for this program.) More info for student applicants is available in Google's Student FAQ. Here's the current pool of ideas for Internet Archive Summer-of-Code projects. (We're open to other ideas, as well.) Students apply via Google's application page. The Archive is an amazing and unique place to work: a non-profit internet library, building a series of one-of-a-kind digital collections, often in partnership with much older and larger institutions like university and national libraries. Yet we have much of the mindset of a technology startup. Let me know if I can answer any questions about these opportunities. Technorati Tags: internet archive, jobs, heritrix, wayback, nutch, nutchwax, java, summer of code «» (0) comments
2006-04-26
Ravings of the insane: Sun's Java version numbering
Sun: JavaTM SE 6, Platform Name and Version Numbers Wherein we learn that...
Technorati Tags: java, sun, idiocy, jdk, j2se «» (1) comments
2006-04-19
DearAOL: You go, girl! DearEFF: WTF?
EFF Fundraiser: "Email -- Should the Sender Pay?", a debate, Thursday April 20th at the Roxie Film Center, San Francisco In light of AOL's adopting a "certified" email system, EFF is hosting a debate on the future of email. With distinguished entrepreneur Mitch Kapor moderating, EFF Activist Coordinator Danny O'Brien and renowned tech expert Esther Dyson will discuss the potential consequences if people have to pay to send email. Would the Internet deteriorate as a platform for free speech? Would spam or phishing decline?I'm disappointed with the EFF's participation in the DearAOL whiny-letter-campaign against the AOL/GoodMail sender-pays anti-spam initiative. There are plenty of big threats to our online freedoms; a private experiment in using micropayment postage to deter spam shouldn't rate for any of the EFF's limited attention. So I'll be attending this debate, curious as to how the EFF got enlisted in such a dubious campaign. A version of Esther Dyson's case for trying sender-pays: Esther Dyson in the NYTimes: You've Got Goodmail I also go over some of the reasons I support email postage as a worthwhile tactic against spam in comments at EFF Chairmain Brad Templeton's blog. Technorati Tags: eff, aol, spam, goodmail, debates, epostage, sender pays, antispam «» (0) comments
2006-04-15
Immigration reform angles
Debates over immigration are so hackneyed I usually find it hard to pay any attention. So I felt lucky to come across two pieces with well-reasoned, subtle, important points in the last couple of days. At The New Republic, the staff editorial That's Hospitality makes a persuasive case that the "guest worker" provisions of recent proposals are un-American: The problem with Bush's plan lies in the term--and the concept of--'guest workers,' because there is little that is more antithetical to the American ideal than a guest worker. While there are dangers in romanticizing this country's immigrant heritage, it is an unmistakable part of the national ethos. For generations, immigrants have come to the United States in search of a better life. In the process, they often remake themselves--as Americans. Even those who are here illegally, and whom we call illegal immigrants, can transcend that identity--or at least see their children who are born here transcend it.TNR also mentions the cautionary experience of Europe and a better alternative, sponsored by Ted Kennedy and John McCain, which ensures any temporary workers have a path to citizenship. The second piece -- a blog entry Immigrants and "Low Wage" Jobs (HT: Marginal Revolution) -- is a cynical and economically-literate take which doesn't fall neatly into the usual pro- or anti- immigration poses. A sample: There is another side to this debate that gets less attention. The fact that immigrants are mostly less-skilled is not an accident. The current "die at the border" policy (so-called because you get the opportunity to work in the United States if you are willing to risk death in a dangerous border crossing) ensures that the flow of immigrants will be primarily less-skilled workers. Workers in developing countries with few employment opportunities might be willing to take this risk, in addition to the risk that they could be subsequently deported if they get picked up for a traffic ticket or some similar offence.This post made me think anew about the shape of immigration policy, and that's saying something. Technorati Tags: immigration, guest workers, wages, economics, tnr, unamerican, beatthepress «» (0) comments
2006-03-18
Web 2.0's MS Access killer?
7 Minute Screencast of Dabble DB's Under The Radar Demo (via TechCrunch) Very nice. Beautiful interface for common DB creation/evolution tasks. It's even Smalltalk under the (server-side) hood. What's not to like? Technorati Tags: dabbledb, screencast, demo, database, access «» (0) comments
2006-03-11
"Bong Hits 4 Jesus"
Reuters @ Yahoo:Court upholds "Bong Hits 4 Jesus" student banner SAN FRANCISCO (Reuters) - An Alaska high school violated a student's free speech rights by suspending him after he unfurled a banner reading 'Bong Hits 4 Jesus' across the street from the school, a federal court ruled on Friday. Principal Deborah Morse seized the banner and suspended the 18-year-old for 10 days, saying he had undermined the school's educational mission and anti-drug stance. "Public schools are instrumentalities of government, and government is not entitled to suppress speech that undermines whatever missions it defines for itself," Judge Andrew Kleinfeld wrote in the court's opinion.Principal Morse should be sentenced to a full semester of her own school's government/civics class. Or would that violate the 8th amendment? Technorati Tags: free speech, censorship, schools «» (0) comments
2006-03-10
Voltaire's prayer: "O Lord, make my enemies ridiculous."
WSJ: Blame It on Voltaire: Muslims Ask French To Cancel 1741 Play A municipal cultural center here on France's border with Switzerland organized a reading of a 265-year-old play by Voltaire, whose writings helped lay the foundations of modern Europe's commitment to secularism. The play, 'Fanaticism, or Mahomet the Prophet,' uses the founder of Islam to lampoon all forms of religious frenzy and intolerance.In the play's original era, the Catholic Church also sought to ban it -- I presume Mohammad was just a conveniently foreign stand-in for aspects of local religious authorities (or all religions) that Voltaire wanted to mock. Why can't the world be filled with 1.5 billion devout followers of Voltaire? We might deduce some of the tenets of this hypothetical Voltairean faith by considering some Voltaire quotes -- bits of the Voltairean scripture, as it were:
Technorati Tags: voltaire, mohammad, mahomet, religion, god, drama, free speech, offensiveness, islam, muslims «» (0) comments
2006-03-05
More on matchmarks in Regex Powertoy
The previous post mentioned Regex Powertoy matchmarks as a way to capture all settings to reproduce a bug. Of course, a matchmark can also be used to save useful or interesting regular expressions (and example target text) as web bookmarks, such as on del.icio.us and its ilk. For example, the Perl 'perlre' regular expressions documentation contains the following warning:
WARNING: particularly complicated regular expressions can take
exponential time to solve because of the immense number of possible
ways they can use backtracking to try match. For example, without
internal optimizations done by the regular expression engine, this will
take a painfully long time to run:
Here's a matchmark representing that operation, with Regex Powertoy animation turned on:
'aaaaaaaaaaaa' =~ /((a{0,5}){0,5})*[c]/You can watch the red probe cursor -- indicating which character of the target input text is currently being tested against the regex -- bounce around, banging against the end of the text and backtracking, for hours. Turning off animation speeds things up considerably, but the ultimate rejection of any matches still takes tens of seconds if not minutes: the final tally is 18,124,859 probes to test the match. Technorati Tags: regex, powertoy, regexp, reference, tips «» (0) comments
Regex Powertoy Bugfixing
Regex Powertoy had a bug where capturing groups inside unmatched alternations would prevent group details from displaying properly, when clicking on a match. It's fixed now, but this matchmark would reproduce the problem -- clicking on the single match would show no group details. Now, the details show -- and any groups unmatched aren't shown at all in the detail view. Regex Powertoy more or less works as long as you've got a modern browser and Java applet support at the "5.0" (aka "JDK 1.5") level. Any bug/glitch reports are appreciated -- and if they're specific to a certain regex pattern, target input, or other settings, you can use the 'matchmark' function to convert your settings to an URL for easy reporting. Technorati Tags: regex, powertoy, regexp «» (0) comments
2006-02-13
TinyURLs are evil URLs
TinyURLs are awful, for usability, for stability of reference, and for browsing safety. Please don't use them in wikis, email, or anywhere. The problems:
(A TinyURL competitor, SnipURL, also lets the creator of a short URL modify it in the future -- making it possible to popularize a SnipURL, have it pass manual review, and then change to a problem URL at any arbitrary time in the future.) There is very little information at the sites of TinyURL or its competitors to assess the long-term stability and trustworthiness of these services -- but even if the service were run by a large venerable institution with an impeccable reputation, most of these problems would remain. And other problems would arise, as venerable institutions are subject to social and political pressures that could make them more willing to, for example, censor or redirect certain short URLs. (If the Chinese Communist Party were to demand that a TinyURL to a dissident page get remapped to a state propaganda page, the same large stable institutions most likely to provide long-lived servers are also most likely to comply to authoritarian change requests.) URLs should be naked, as endowed by their creators with the inalienable rights of meaningfulness, transparency, and stability. Friends don't let friends use TinyURLs. Technorati Tags: tinyurl, snipurl, urls, security, linking, spam, malware «» (14) comments
2006-02-12
Daniel S. Wilkerson, Elsa/Oink/Cqual++ @ CodeCon 2006, 4:45pm Sunday
And the very last prejudicial CodeCon session preview: Daniel S. Wilkerson: Elsa/Oink/Cqual++, (scheduled for but starting much later than) 4:45pm Sunday @ CodeCon 2006
Daniel Wilkerson hooked Elsa [a C/C++ parser] and Cqual [a type-based analysis tool that provides a lightweight, practical mechanism for specifying and checking properties of C programs] together to make Cqual++. It resides in a kind of super-project called Oink which is designed to allow multiple backends for Elsa to cooperate (the only example of which presently is Cqual++). For example, the dataflow analysis is pretty generic and other dataflow-based C++ analyses could be written using it and added to Oink.Nothing to speculate here. Entry only for completeness sake. Technorati Tags: codecon, codecon2006, cqual, elsa, oink, dataflow, debugging, «» (0) comments
Adam Souzis, Rhizome @ CodeCon 2006, 4pm Sunday
Continuing prejudicial CodeCon session previews: Adam Souzis: Rhizome, (scheduled for) 4pm Sunday @ CodeCon 2006
Rhizome is a open source project written in Python which consists of a stack of components:I love wikis. I can't wait to see effective ways to allow wiki-style editting of (slightly) more-structured data than the free-form text for which wikis are known. But anything RDF tends to make my eyes glaze over. Even when there's something RDF-ish that's interesting, it's couched in terminology and indirection that hides the interesting parts. So it's the aspects of Rhizome that insulate users from RDF -- extracting RDF automatically from familiar syntaxes, making RDF more amenable to usual XML operations -- that I look forward to seeing in this presentation. I'd be tickled pink if the demo showed a plausible interface for unsophisticated users -- for example, enthusiasts in non-technical fields -- to generate useful RDF about their fields... but I'm not holding my breath. Technorati Tags: codecon, codecon2006, rhizome, rdf, wiki, metadata «» (0) comments
Nathaniel Smith, Monotone @ CodeCon 2006, 3:15pm Sunday
Continuing prejudicial CodeCon session previews: Nathaniel Smith: Monotone, (scheduled for) 3:15pm Sunday @ CodeCon 2006
monotone is a free distributed version control system. it provides a simple, single-file transactional version store, with fully disconnected operation and an efficient peer-to-peer synchronization protocol. it understands history-sensitive merging, lightweight branches, integrated code review and 3rd party testing. it uses cryptographic version naming and client-side RSA certificates. it has good internationalization support, has no external dependencies, runs on linux, solaris, OSX, windows, and other unixes, and is licensed under the GNU GPL.I'm a secure-hash-for-content-identification fetishist, so I really like Monotone's approach of naming all versions by their SHA1 hash. Also, despite my experience being almost exclusively with centralized version control like CVS, MS SourceSafe, and SVN, I find systems like Monotone with no inherent central server or canonical version intellectually appealing. But, since decentralized systems can be harder to explain via a childishly simple model, and can obscure the focal points for casual understanding/contribution, I doubt they will often be the right choice for projects that seek a wide audience. Still, I'd love to see some vociferous advocacy of the Monotone model in the presentation. Also, if any of the tools, especially any visual interfaces, help tame the complexity of a centerless system. The Monotone docs claim their internal 'netsync' protocol is far more efficient than rsync or Unison, so I'm curious if it is a separable piece applicable elsewhere. Technorati Tags: codecon, codecon2006, monotone, version control, cvs, sha1 «» (0) comments
Davies, Newman, O'Connor, & Tam: Deme @ CodeCon 2006, 1:15pm Sunday
Continuing prejudicial CodeCon session previews: Todd Davies, Benjamin Newman, Brendan O'Connor, Aaron Tam: Deme, 1:15pm Sunday @ CodeCon 2006
Deme is being developed for groups of people who want to make decisions democratically and to do at least some of their organizational work without having to meet face-to-face. It provides the functionality of message boards and email lists for discussion, integrated with tools for collaborative writing, item-structured and document-centered commentary, straw polling and decision making, and storing and displaying group information. It is intended to be a flexible platform, supporting various styles of group interaction: dialogue and debate, cooperation and management, consensus and voting…This is an area of longstanding interest to me; creating online spaces that could reach convergence on a consensus, with the help of discussion and ranking widgetry, was a big theme at the founding of Activerse (1996-1999), though we eventually went in the direction of a decentralized buddy list. The complementary-and-contrasting yin-and-yang of software for enabling online groups is: (1) Technical decisions do influence the character of a community and the results it produces, including whether it is welcoming of newcomers, maintains an institutional memory, converges or diverges on major issues, fans or suppresses 'flaming' communication, and so forth. The Arrow Impossibility Theorem demonstrates that every voting system exhibits 'artifacts' where idealized goals cannot be met simultaneously; larger collaborative systems, which go beyond voting to include other forms of interaction, both magnify the potential for artifacts, and offer the chance for norms of behavior and other feedback to ameliorate any untoward gaming. But... (2) Programmers consistently overestimate the importance of technical measures, over-engineering in anticipation of problems that may never arise, and inappropriately reaching for technical solutions to whatever problems do come up. In Wikipedia founder Jimmy Wales' stump speech, he likens this tendency to caging restaurant-goers to protect them from each others' steak knives. Solutions like Deme have to be conscious of the influence of technical design, but not enthralled by its possibilities. The proper balance is difficult to determine -- and is certainly different for different communities. Deme has four presenters listed, each tackling a different aspect of their mission or technology. I predict they run long and get truncated. As aspect I don't see mentioned in their materials is the transparent management of organization resources -- especially finances. I've long wanted to see someone develop what would essentially be an open, multiuser, web-based QuickBooks for distributed organizations. Every cent inbound and out could be tracked, linked to the group goals and decisions, and mapped back to the contributors who made things happen. This would also open new avenues for voting on priorities by contributing or allocating contributions. The Deme team might find it very helpful to review Christopher Allen's series of articles on Collective Choice:
Quinn Weaver, Dido @ CodeCon 2006, 12:30pm Sunday
Continuing prejudicial CodeCon session previews: Quinn Weaver: Dido, 12:30pm Sunday @ CodeCon 2006
Dido grew out of a frustration with the open-source telephony platform Asterisk's dialplan system... I quickly realized that what I wanted to do--reordering menu options in voice menu, by popularity--was impossible in Asterisk... I ended up creating Dido, a radically new system that makes use of declarative XML templates, interspersed with Perl code that generates more XML. The result is a programming model that mimics the way dynamic Web pages are written...Very little descriptive info on the project website, but from the above I'm guessing the essence is: make call-in voice-response systems as easy to author as dynamic web pages, without arbitrary limitations as imposed by previous offerings. The code is available for download, and "[t]he audience will be able to call into the demo system during the talk, using their cell phones, and traverse it independently" -- which is exactly what a demo of this functionality should include. For what it's worth, there's nothing wrong with this project name! No obvious name collisions in the tech domain nor prominent untoward connotations in other meanings of 'dido'. «» (0) comments
2006-02-11
Meredith L. Patterson, Query By Example @ CodeCon 2006, 4:45pm Saturday
Continuing prejudicial CodeCon session previews: Meredith L. Patterson: Query By Example, 4:45pm Saturday @ CodeCon 2006
Query By Example brings supervised machine learning into the realm of SQL in order to provide intuitive, qualitative queries. Within your query, you list a few examples which are LIKE the kind of rows you're looking for, and a few more which are NOT LIKE the kind of rows you're looking for, and using a fast, flexible machine learning algorithm, the database will automatically find rows which are similar to what you're interested in.This was a graduate student project that got sponsored by Google's Summer of Code and has added the above-described new capability to PostgreSQL. Patterson gave a great presentation about analyzing (and even making!) DNA at last year's CodeCon, and Query By Example looks useful for a lot of common datamining operations, such as the recommendation systems of online retailers and content-aggregators. It's apparently based on a support vector machine, which looks worth the effort to truly understand (though I don't yet). It's something about calculating the best dividing plane between two sets of example coordinates in a muli-dimensional vector space, then using that plane to classify other coordinates. I would guess that when eventually generalized to text, the technique would view the presence or absence of any interesting term as an independent dimension with a binary coordinate. Update (8:35pm Saturday): I almost forgot to mention: this is another problematic project name. (That makes 6 of the first 10 presentations that fall short of my standards for effective names.) There are already concepts that go by "Query By Example" in the SQL and full-text realms. Now, the name may make more sense for a system, like the one presented, where exact rows (or documents) are used as the 'query' -- as opposed to the prior meanings where you provide some fragmentary field values to match. But, squatter's rights count, and I think Patterson's QBE might be underestimated by SQL-heads who see "Query by Example" and think of the previous 'example values' meaning rather than 'example items'. Which would be too bad, because this is a very neat capability backed by very interesting and general algorithms. Reading more about the support vector machine approach, I see that it can be used, among other things, for training a web search engine based on implicit user feedback. I strongly suspect such feedback has become even more important than the link structure of the web in commercial search engine operation. During the Q&A period, the last question actually made the presenter cry -- but in a good way. CodeCon program chair Len Sassaman asked presenter Meredith Patterson, who he met at last year's conference, to marry him. She accepted. Not something you often see at a technical conference, but CodeCon has always been a bit special. Technorati Tags: codecon, codecon2006, qbe, query by example, collaborative filtering, recommendations, support vector machine, marriage proposals, postgreSQL, sql «» (0) comments
Michael J. Freedman, OASIS (Overlay Anycast Service InfraStructure) @ CodeCon 2006, 4pm Saturday
Continuing prejudicial CodeCon session previews: Michael J. Freedman: OASIS (Overlay Anycast Service InfraStructure), 4pm Saturday @ Codecon 2006
OASIS (Overlay Anycast Service InfraStructure) is a locality-aware server selection infrastructure. At a high level, OASIS allows a service to register a list of servers, and then, for any client IP address, answers the question, ``Which server should the client contact?'' Server selection is primarily optimized for network locality, but also incorporates factors like liveness and, optionally, load. OASIS might, for instance, be used by CGI scripts to redirect clients to an appropriate download site for large files. It could be used by IP anycast proxies to locate servers. Currently, in addition to a simple web interface, we have implemented a DNS redirector that performs server selection upon hostname lookups, thus supporting a wide range of unmodified legacy client applications.Their homepage demo apparently is supposed to show a circle on the embedded map showing my location -- it's not working for me here from CodeCon, even after typing in my external IP address. From the overview, it's clear that the reference solution OASIS has in mind for comparison is probing a new IP address from multiple sites on-demand at the moment they want to know the right server. But, they report this solution has problems: latency and too much redundant traffic probing IPs that are near each other. So OASIS is constantly mapping network blocks in the background, and remembering and updating its results for lags and geographic location guesses. Because this effort is ongoing, amortized over time and over diverse applications, the costs in latency and traffic are less than the naive on-demand solution. In fact, as more applications share the same location architecture, the marginal cost for each new one drops. There would seem to be some overlap with the constant, distributed net-mapping done by the net DIMES project based at Tel-Aviv University. There's already a OASIS abbrieviation in use in technical/internet circles: "a non-profit, international consortium that creates interoperable industry specifications based on public standards such as XML and SGML." So yet again at CodeCon, this is a bad project name on uniqueness grounds alone. (Not to mention: how is a worldwide always-on active map of the Internet anything like a remote desert oasis?) Do we need a boot camp that teaches engineers to pick better evocative and unique project names? Technorati Tags: codecon, codecon2006, OASIS, geolocation, internet, topology «» (0) comments
David Barrett:, iGlance @ CodeCon 2006, 3:15pm Saturday
Continuing prejudicial CodeCon session previews: David Barrett: iGlance, 3:15pm Saturday @ Codecon 2006
Basically iGlance tries to recreate the advantages of "being there", but remotely, over the internet. In essence I asked "What's so great about being physically present? Well, I can see you, I can talk to you, I can see your computer, I can use your computer... Heck, I can do all that online!" With iGlance, you can continue using the same "social tools" you've refined for when physically present, but from any internet connection. Peeking over a cubical wall is replaced with glancing at your buddy list. Yelling across the room is push-to-talk. Screen sharing is asking you to sit at my keyboard. Everything is oriented around this central metaphor.More deja vu for me. This yearning to recreate the benefits of physical co-presence online, by reusing the familiar metaphors of co-presence, was also what animated my Austin-based Internet startup Activerse (Web 1.0 era, 1996-1999). It appears iGlance is an evolution of classic net collaboration tools, integrated, updated to assume VOIP (via push-to-talk) and webcams, and open-sourced. It's not clear how colleagues' current IP addresses are found -- is there a dependency on a lookup service @ quinthar.com? To the extent it includes nice features and unifying philosophy, I would expect its winning techniques to be eventually adopted by the big IM networks and sotware packages. Technorati Tags: codecon, codecon2006, iGlance, activerse, presence «» (0) comments
Hansen & Thiede, Djinni @ CodeCon 2006, 1:15pm Saturday
Continuing prejudicial CodeCon session previews: Robert J. Hansen, Tristan D. Thiede: Djinni, 1:15pm Saturday @ Codecon 2006
Djinni is an extensible, heavily documented framework for the efficient approximation of problems generally thought to be unsolvable [in polynomial time]. It doesn't give you the optimal solution, but generally gives you very close to it, and in a very reasonable time frame.Djinni is apparently based on "a new approximation algorithm for NP-complete problems" by Drs. Jeff Ohlmann and Barrett Thomas of the University of Iowa. However, I can't find in the Djinni docs a simple explanation of what their insight was, in contrast to what came before: how it's different, how it might be better. An expert might be able to recognize the novelty by parsing the Djinni User Guide, but I can't. The writing in the User Guide (which is actually more of a tutorial walkthrough applying Djinni to Boggle) suggests Mr. Hansen tends a bit towards discursive flourishes. (Example: "Bad or out-of-date documentation is something no programmer should tolerate. Far better there be no documentation at all than significantly out-of-date documentation."). This could make his presentation entertaining... or awkward as whimsical asides fall flat. We'll see. Update (8:13pm Saturday): Presenter reported that the Ohlmann/Thomas approach is qunatifiably better than another popular solution, whose name I neglected to note, which was also denigrated as being comparatively complex. The whimsical tendencies of the presenters did get laughs... some genuine, some uncomfortable. Technorati Tags: codecon, codecon2006, djinni, np-complete, boggle, «» (0) comments
Wilkerson & McPeak, Delta @ CodeCon 2006 12:30pm Saturday
Continuing prejudicial CodeCon session previews: Daniel S. Wilkerson, Scott McPeak: Delta, 12:30pm Saturday @ CodeCon 2006
Delta assists you in minimizing "interesting" files subject to a test of their interestingness. A common such situation is when attempting to isolate a small failure-inducing substring of a large input that causes your program to exhibit a bug.'Delta' has a number of glowing testimonials from the gcc team and users on their project page. The two big wins there seem to be: (1) When a giant range of proprietary code shows a gcc bug, minimizing it via delta makes it concisely reportable, where it couldn't be effectively reported at all otherwise; (2) people often submit larger-than-minimal trigger cases, and delta is used to (automatically always?) minimize these. Very neat. There must be other applications, too. Considering yesterday's theme of dissecting novel malware, perhaps this could be used to discover the minimal effective countermeasures against a new threat? (Apply all draconian countermeasures. Loosen progressively until finding smallest set that works against the threat.) Or bioinformatics? One can easily imagine real heredity, mutation, and immunology working this way at the microscopic level to explore the survivability possibility space. I'm most curious to see the actual efficient 'winnowing' processes used by the tool. (I hope there's a visualization or animation of some sort.) Is it completely systematic, guaranteed to determine the smallest possible trigger case possible by dropping lines? That seems impossible, given the size of input files: a thousand-line input has 2^1000 possible minimizations, too many to search exhaustively. How many trials does it run, how fast, in a typical minimization (independent of the user-supplied interestingness predicate)? Perhaps there's a random element -- so that repeated reruns (with different seeds) or a willingness to wait longer could discover different/better minimal cases. Update (Saturday 1:26pm): The search for lines that are droppable is dumb and deterministic -- essentially a binary search for logarithmically-sized subranges that can be eliminated. It's thus somewhat sensitive to the alignment of content with respect to the subranges. Its performance is thus improved a lot by a 'flattening' preprocessing which manages to group units of the input (eg C code blocks) into a single line. Wilkerson suggested a randomization element might help. This project, too, deserves a better name. (Am I obsessed with names or what?) Something like 'occamizer'. It's available and descriptive. Technorati Tags: codecon, codecon2006, delta, debugging, gcc «» (0) comments
|
News and opinion on technology, culture, business, politics, and the hidden meaning of it all.
About Gordon Mohr Archives
|

 RSS Feed
RSS Feed